
Anthropic’s cutting-edge AI model, Claude 3 Opus, has achieved a significant milestone by achieving the top spot on the Chatbot Arena leaderboard. With this victory, the standings have changed significantly, moving OpenAI’s ChatGPT-4 to the runner-up spot for the first time since the competition’s start last year.
The LMSYS Chatbot Arena takes an original tack when it comes to benchmarking AI models, putting a strong emphasis on human judgment. In a blind test, participants must evaluate and rank the results of two different models given the same prompts.

This is an amazing accomplishment for Claude 3 because OpenAI’s GPT 4 has dominated this benchmark for so long that any other AI model that comes near is referred to as the “GPT 4 class.”
Claude outperforms GPT 4 in these results; however, it’s important to note that the scores of the two models are extremely similar. Since GPT 4.5 is anticipated to be published very soon, Claude 3 might not maintain this position long.
Run by LMSys, the big Model Systems Organization, the Chatbot Arena has a variety of big language models participating in random, anonymous combat. Since its origin last year, the benchmark has gathered north of 400,000 user votes. Since then, the artificial intelligence models from OpenAI, Google, and Anthropic have been positioned in the main 10. However, numerous open-source models have also lately emerged in the top places, like Mistral’s and Alibaba’s solutions.
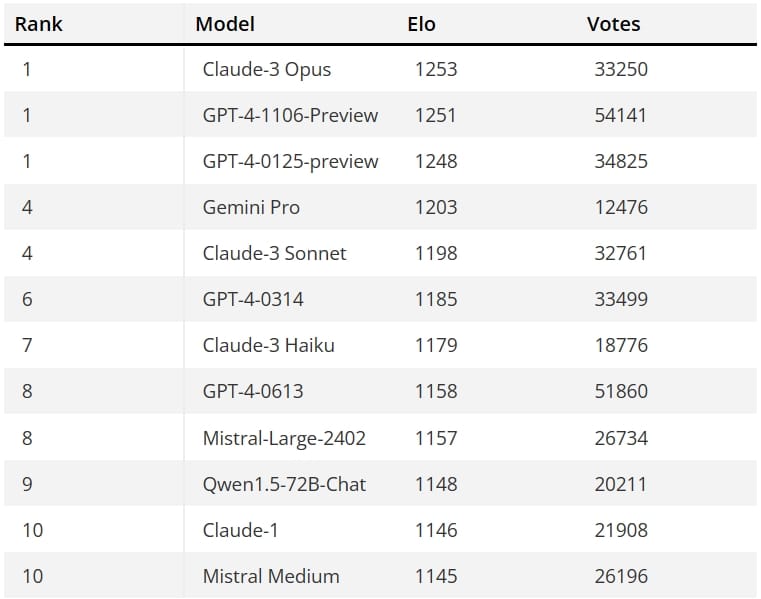
This benchmark determines each player’s ability level using the Elo method, widely used in chess and e-sports activities. With one exception: the AI models that power these chatbots are the participants in this instance rather than actual people.
With more than 70,000 fresh votes, Claude 3 Opus—the largest model in the Claude 3 family—took the top spot on the scoreboard. The nicest thing is that the performance of the smaller Claude 3 versions was as good. The smallest model in the series, the Claude 3 Haiku, is designed to operate on consumer electronics like Google’s Gemini Nano. It produces remarkable outcomes without being appreciably bigger than Claude Opus or GPT 4.
All three Claude models could secure the top ten positions in these benchmarks. Opus was first, Sonnet and Gemini Pro in fourth place, and Haiku, using an earlier version of GPT 4, in sixth place.

